
Grounded scene understanding from event streams. This work presents Talk2Event, a novel task for localizing objects from event cameras using natural language, where each unique object in the scene is defined by four key attributes: 1Appearance, 2Status, 3Relation-to-Viewer, and 3Relation-to-Others. We find that modeling these attributes enables precise, interpretable, and temporally-aware grounding across diverse dynamic environments in the real world.
Event cameras offer microsecond-level latency and robustness to motion blur, making them ideal for understanding dynamic environments. Yet, connecting these asynchronous streams to human language remains an open challenge. We introduce Talk2Event, the first large-scale benchmark for language-driven object grounding in event-based perception. Built from real-world driving data, we provide over 30,000 validated referring expressions, each enriched with four grounding attributes -- appearance, status, relation to viewer, and relation to other objects -- bridging spatial, temporal, and relational reasoning. To fully exploit these cues, we propose EventRefer, an attribute-aware grounding framework that dynamically fuses multi-attribute representations through a Mixture of Event-Attribute Experts (MoEE). Our method adapts to different modalities and scene dynamics, achieving consistent gains over state-of-the-art baselines in event-only, frame-only, and event-frame fusion settings. We hope our dataset and approach will establish a foundation for advancing multimodal, temporally-aware, and language-driven perception in real-world robotics and autonomy.

Figure. We leverage two surrounding frames to generate context-aware referring expressions at t0, covering appearance, motion, spatial relations, and interactions. Word clouds on the right highlight distinct linguistic patterns across the four grounding attributes.
| Dataset | Venue | Sensor | Scene Type | Scenes | Objects | Expr. | Avg Len. | δa | δs | δv | δo |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RefCOCO+ | ECCV'16 |  | Static | 19,992 | 49,856 | 141,564 | 3.53 | ✓ | ✗ | ✗ | ✗ |
| RefCOCOg | ECCV'16 | | Static | 26,711 | 54,822 | 85,474 | 8.43 | ✓ | ✗ | ✗ | ✓ |
| Nr3D | ECCV'20 |  | Static | 707 | 5,878 | 41,503 | - | ✓ | ✗ | ✗ | ✓ |
| Sr3D | ECCV'20 | | Static | 1,273 | 8,863 | 83,572 | - | ✓ | ✗ | ✗ | ✓ |
| ScanRefer | ECCV'20 | | Static | 800 | 11,046 | 51,583 | 20.3 | ✓ | ✗ | ✗ | ✓ |
| Text2Pos | CVPR'22 |  | Static | - | 6,800 | 43,381 | - | ✓ | ✗ | ✓ | ✗ |
| CityRefer | NeurIPS'23 | | Static | - | 5,866 | 35,196 | - | ✓ | ✗ | ✗ | ✓ |
| Ref-KITTI | CVPR'23 | | Static | 6,650 | - | 818 | - | ✓ | ✗ | ✓ | ✗ |
| M3DRefer | AAAI'24 | | Static | 2,025 | 8,228 | 41,140 | 53.2 | ✓ | ✗ | ✓ | ✗ |
| STRefer | ECCV'24 | | Static | 662 | 3,581 | 5,458 | - | ✓ | ✗ | ✗ | ✗ |
| LifeRefer | ECCV'24 | | Static | 3,172 | 11,864 | 25,380 | - | ✓ | ✗ | ✗ | ✗ |
 Talk2Event Talk2Event | Ours |
|
Dynamic | 5,567 | 13,458 | 30,690 | 34.1 | ✓ | ✓ | ✓ | ✓ |
 Talk2Event Dataset
Talk2Event DatasetData examples of the Car class under the Daytime condition in our dataset.
| Event Stream | RGB Frame | Referring Expression |
|---|---|---|
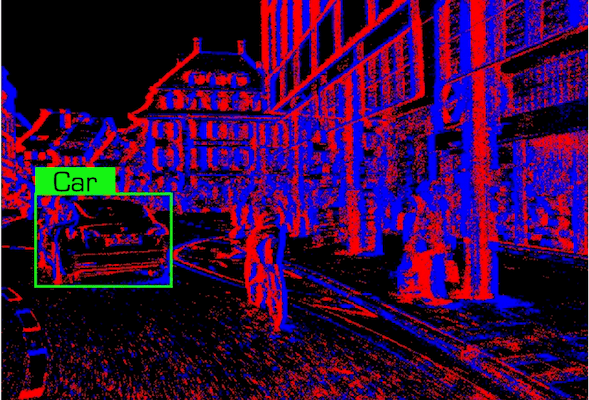 |
 |
 |
 |
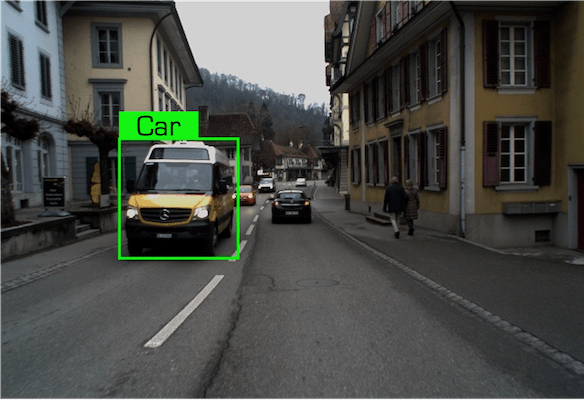 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
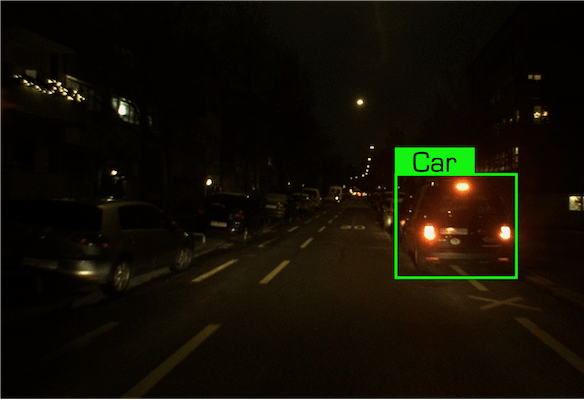
Data examples of the Car class under the Nighttime condition in our dataset.
| Event Stream | RGB Frame | Referring Expression |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
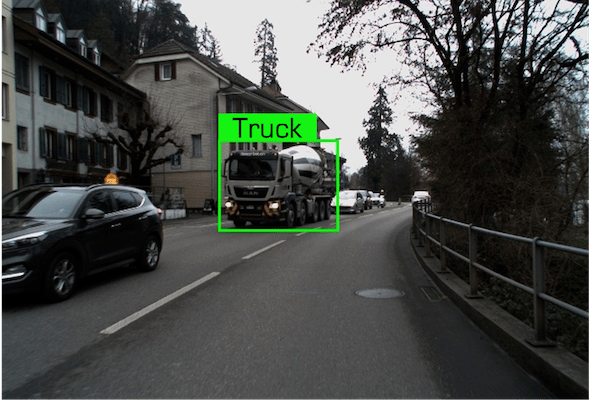
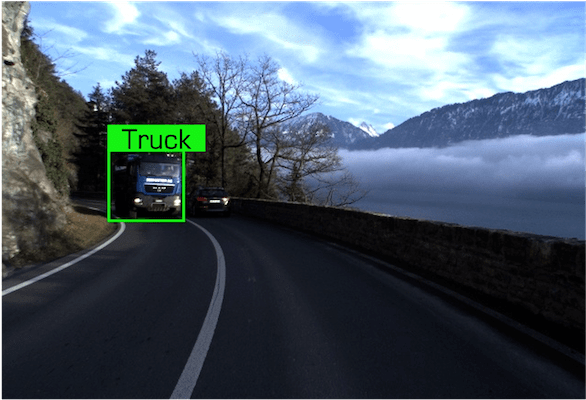
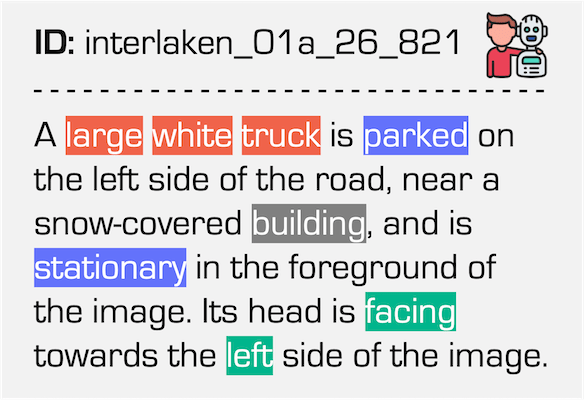
Data examples of the Truck class under the Daytime condition in our dataset.
| Event Stream | RGB Frame | Referring Expression |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
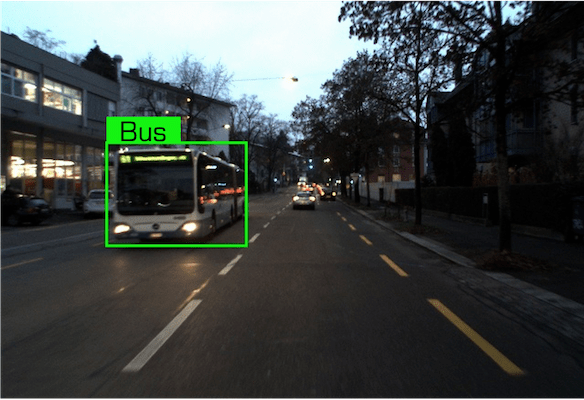
Data examples of the Bus class under the Daytime condition in our dataset.
| Event Stream | RGB Frame | Referring Expression |
|---|---|---|
 |
 |
 |
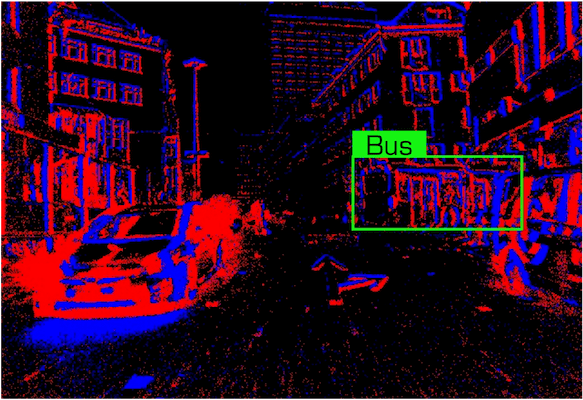 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Data examples of the Pedestrian class under the Daytime condition in our dataset.
| Event Stream | RGB Frame | Referring Expression |
|---|---|---|
 |
 |
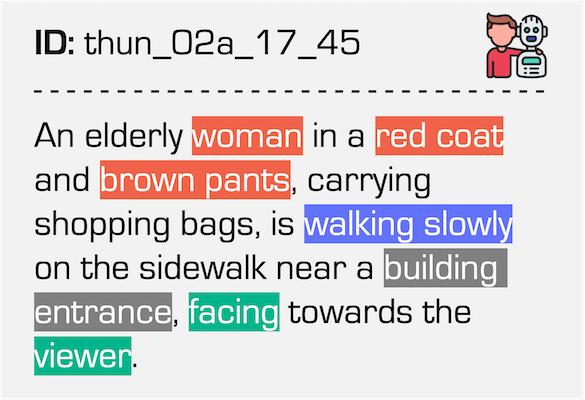 |
 |
 |
 |
 |
 |
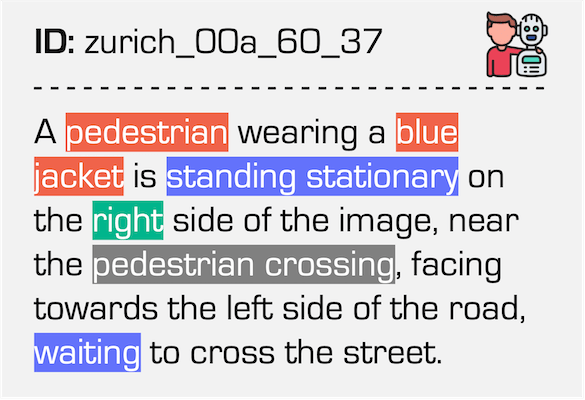 |
 |
 |
 |
 |
 |
 |
Data examples of the Pedestrian class under the Nighttime condition in our dataset.
| Event Stream | RGB Frame | Referring Expression |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
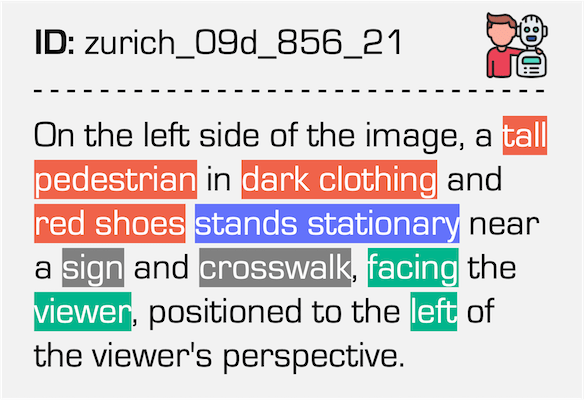 |
Data examples of the Bicycle class under the Daytime condition in our dataset.
| Event Stream | RGB Frame | Referring Expression |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Data examples of the Motorcycle class under the Daytime condition in our dataset.
| Event Stream | RGB Frame | Referring Expression |
|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
@inproceedings{liang2025pi3det,
title = {{Talk2Event}: Grounded Understanding of Dynamic Scenes from Event Cameras},
author = {Lingdong Kong and Dongyue Lu and Ao Liang and Rong Li and Yuhao Dong and Tianshuai Hu and Lai Xing Ng and Wei Tsang Ooi, Benoit R. Cottereau},
booktitle = {Advances in Neural Information Processing Systems},
year = {2025},
}